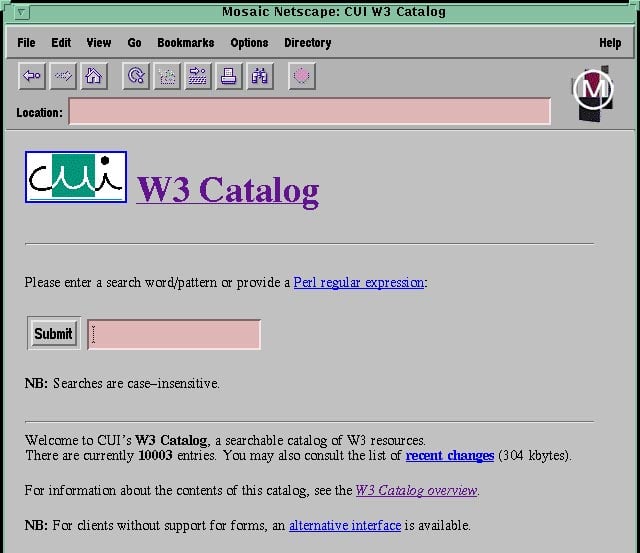
A web, ahogyan ma ismerjük, elképzelhetetlen lenne a keresőmotorok nélkül. Ma már teljesen természetes, hogy a keresőmotorok pillanatok alatt rendszerezik a web hatalmas adatmennyiségét. Bár napjainkban a Google és a Bing uralja a piacot, a történelemben létezett egy idő, amikor a webes tartalom megtalálása még gyerekcipőben járt. 1993. szeptember 2-án azonban ezen a helyzeten gyökeresen változtatott a világ első primitív keresőmotorja, a W3Catalog. Fedezzük fel, hogyan indult a webes keresés hajnala.
A kezdetek: Egy svájci egyetem különleges ötlete
A web a ’90-es évek elején, a CERN-ben, Tim Berners-Lee munkássága nyomán indult el világhódító útjára. Kezdetben a böngészők rendkívül primitívek voltak, és a tartalmak megtalálása kizárólag kézi listák és a hivatkozások követésével volt lehetséges. Az oldalak listáját manuálisan kellett összeállítani, és ezek a listák gyakran hiányosak voltak. Ezt a problémát ismerte fel Oscar Nierstrasz, a Genfi Egyetem (Centre Universitaire d'Informatique, CUI) kutatója, amikor elindította a W3Catalog nevű projektet. Az egyetem saját szerverén, a Plexus-on keresztül 1993. szeptember 2-án mutatták be a W3Catalog-ot, amit eredetileg „jughead”-nek neveztek. A „kereső” egy Perl-ben írt, egyszerű, konfigurálható csomag, a parscan.pl volt. Ez a program lehetővé tette, hogy a felhasználók ISINDEX-alapú HTML-lekérdezésekkel (query) keressenek az oldalak között. A W3Catalog lényege az volt, hogy rendszeresen letöltötte és egyetlen kereshető fájlba rendezte a weben fellelhető, magas minőségű, kézzel szerkesztett forráslistákat, mint például a CERN által fenntartott WWW Virtual Library.
Az internet hajnalán a webes oldalak rendszerezése és keresése igazi kihívást jelentett.
A W3Catalog lényegében egy hiperhivatkozásokat tartalmazó katalógus volt, amely lehetővé tette a felhasználók számára, hogy kategóriák szerint böngésszenek a weboldalak között. Ez a "kereső" forradalmi volt a maga idejében, mivel ahelyett, hogy a felhasználóknak maguknak kellett volna rátalálniuk az oldalak címeire, a W3Catalog egyetlen, központosított helyen gyűjtötte össze a releváns linkeket.
A W3Catalog működése
A W3Catalog mintegy három éven keresztül működött, mielőtt a ma is ismert, kifinomultabb keresőmotorok, mint a Lycos, az AltaVista, majd később a Google, megjelentek volna a piacon. Bár a W3Catalog működése a mai szemmel nézve primitívnek tűnhet, alapjai meghatározóak voltak a modern keresőmotorok kialakulásában.
A W3Catalog kulcsfontosságú elemei a következők voltak:
- Központosított indexálás: Bár kézzel történt, az oldalak egy helyen való gyűjtése megkönnyítette a felhasználók számára a böngészést.
- Kategorizálás: A releváns tartalmak kategóriákba rendezése a keresés hatékonyságát növelte, ami a mai napig alapvető funkció a különböző weboldal-katalógusok esetében.
A W3Catalog-hoz hasonló, kézi szerkesztésű katalógusok a web kezdeti szakaszában rendkívül fontosak voltak, hiszen ők teremtették meg a rendet a gyorsan növekvő és kaotikus online világban. Az, hogy nem maradt fenn róla eredeti kép, csak a rá hivatkozó oldalakról, jól mutatja, mennyire gyerekcipőben járt még a digitális megőrzés, és a webes történelemírás is. Azonban az öröksége máig érezhető, hiszen ez a kezdeményezés fektette le a webes keresés alapjait, és indította el azt a folyamatot, amely elvezetett a ma ismert, kifinomult keresőtechnológiákhoz.
A fejlődés és a bukás
A W3Catalog alapkoncepciója alig változott a hároméves fennállása alatt. A főbb módosítások az új forráslisták hozzáadására és a „chunking” szkript (ami a listákat külön HTML-szakaszokra darabolta) frissítésére korlátozódtak, hogy az alkalmazkodjon a forrásoldalak formátumának változásaihoz. A W3Catalog népszerűsége ellenére azonban több okból is elavulttá vált:
- Karbantartási nehézségek: A listák kézi nyomon követése, az érvénytelen URL-ek ellenőrzése és a felhasználói kérések megválaszolása túl sok munkát igényelt.
- Törékenység: A chunking szkript túlságosan sérülékeny volt a forráslisták formátumának legapróbb változásaira is, ami hibás találatokhoz vezetett.
- Teljesítményproblémák: A W3Catalog egyszerű, CGI-alapú megvalósítása komoly erőforrásigényes volt. Minden egyes keresés új folyamatot indított, ami újrafordította a Perl kódot és átolvasta a teljes adatbázist. A több megabájtos adatbázis és a másodpercenkénti több kérés a CUI szerverét térdre kényszerítette.
A versenytársak és a tanulság
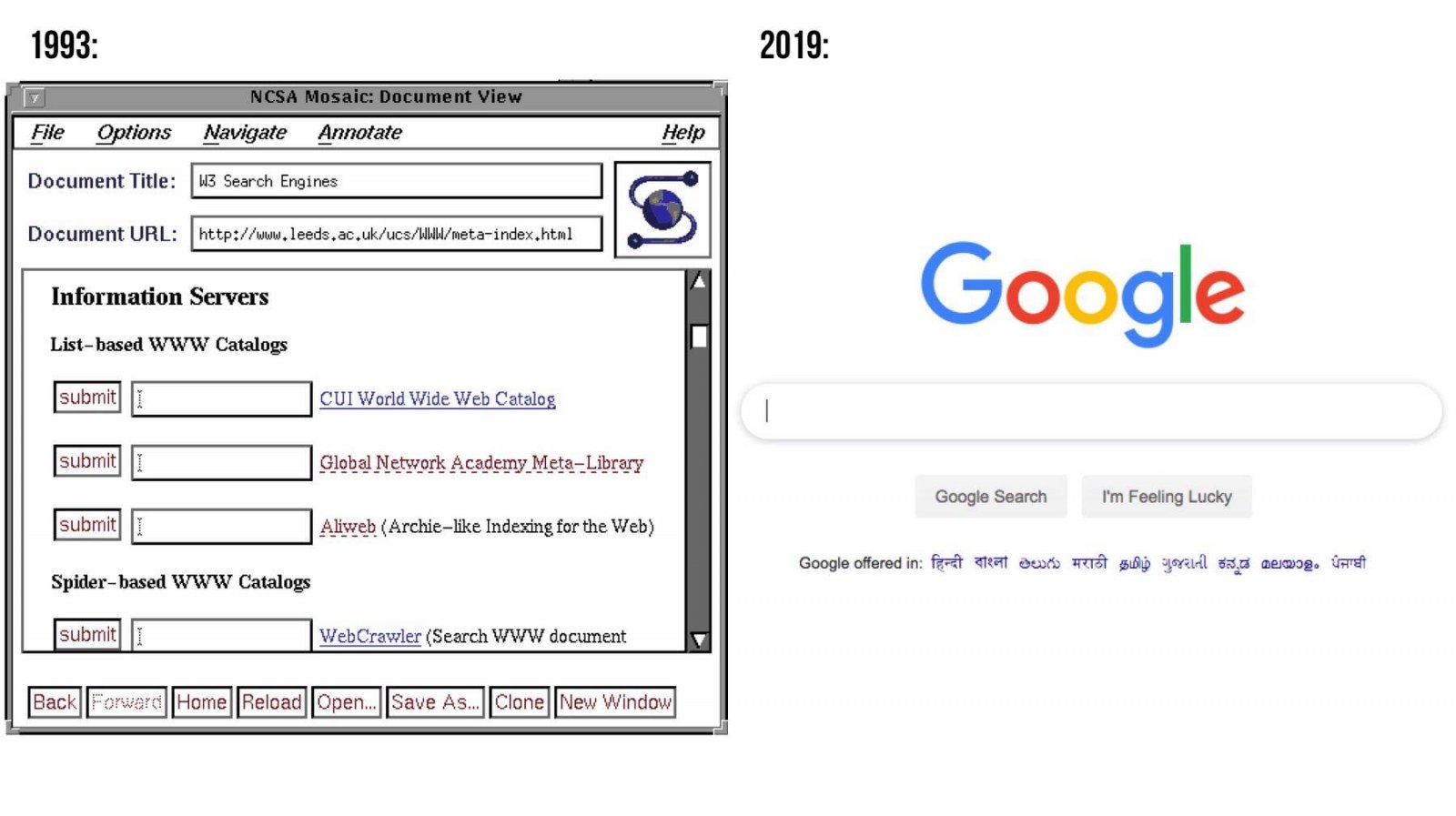
A W3Catalog utolsó napjaiban, 1996-ban már sokkal kifinomultabb és átfogóbb keresőmotorok jelentek meg, mint az AltaVista és a HotBot. Ezek a motorok automatizáltan, robotok (web crawlers) segítségével indexelték a teljes webet, és nagymértékben optimalizált megvalósításokkal működtek. Ezzel a képességekkel a W3Catalog egyszerűen nem tudta felvenni a versenyt, így 1996. november 8-án véglegesen leállították. Oscar Nierstrasz szerint a W3Catalog sikere azt bizonyította, hogy létezik igény a magas minőségű, ember által felügyelt listákra. Bár a W3Catalognak véget ért a korszaka, öröksége tovább él: ez a primitív keresőmotor mutatta meg először, hogy a webes adatok rendszerezése és kereshetősége kritikus a tartalomfogyasztás szempontjából, és ezzel utat nyitott a mai, kifinomult keresőtechnológiák előtt.